
Google Dremel
Discover comprehensive summaries and detailed insights across various topics and themes.
2013
15
Trusted by Many
Year of Publish
What it is about?
Dremel is an architecture that proposes an alternative to record-based querying. It’s idea is to store and fetch records in the form of columns. A tree like nested structure is encoded into to columns in order to reduce the execution time. This is especially helpful in parallel computing where multiple queries perform large-scale database operations.
So Dremel makes 3 key contributions: provide columnar storage for nested data, specifies query language to access columnar data, execution trees approach for aggregate queries
Dremel is suggested to be used along with MapReduce, GFS and FlumeJava. SO they ensured Dremel is interoperable with other tools.
Approach
Data Model
The main idea is that the columnar format must reconstruct to record-based format to support MR. It should also be quick. Dremel supports fields that are repeated, missing and optional. Each field becomes a column and it forms a hierarchy.
Execution
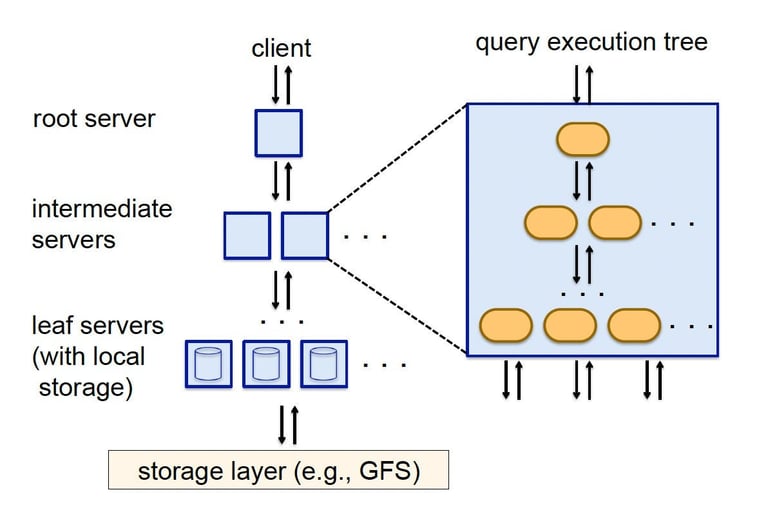
Dremel has root (interacts with user), intermediate nodes (has internal execution trees that computes and performs aggregates) and leaf nodes (access to storage). The root node dispatcher breaks SQL query and passes subqueries to intermediate nodes that in turn breaks it down further and pass it down the tree. This was done to enable parallel processing and reduce execution time.
Storage
Dremel assigns repetition(r) and definition(d) to each field in order to know where it is located in the nested structure, to find repeated and missing fields. A field is encoded as a block of non-NULLs along with r and d values. Then nested records are made into columns by recursing and computing R and D values. To reconstruct them back to record format, Dremel uses Finite State Machine (FSM). FSM starts at the root and consequently finds next fields.
Experiments
Dremel (column storage) proved to have better performance when reading from disk. The execution time was significantly less when MR used column-type of storage compared to MR that uses record-type storage. Aggregates that returns multiple groups benefit from multi-level serving trees. Leaf nodes process 99% of the tablet. If there are less replicas, the likelihood of straggler hindering execution is high. So high replication will solve this by rerunning tasks on other replicas.
Query Language
Dremel’s query language is designed specifically for nested data, columnar data. It produced and preserves nested structure in its output.
Observations
Dremel compliments MR and gives good results when used together. Achieves linear scalability for deeply nested data. All lanes should use column-based data in order to improve speed.
Related Work
Dremel is similar to MapReduce as both tries to address fault tolerance, flexible data model, and in situ data processing. The columnar representation comes from the works published by Abadi and team. Data model and query language is from the studies of nested relations. It mentions other parallel data processing frameworks like Pig, Scope, and DryadLINQ,
Conclusion
Dremel was designed to make analysis of nested data faster by using an efficient columnar storage and serving tree. The R and D allows Dremel to store in columns and reconstruct them back into records without loosing data. Finally, It allows integration with other tools like GFS, MapReduce to make large-scale data processing faster and efficient.
Our Projects
Explore our diverse range of innovative projects.


Project A
Innovative solution for modern challenges.






Project B
Creative approach to community development.