
Google BigQuery
Discover comprehensive summaries and detailed insights across various topics and themes.
2013
15
Trusted by Many
Year of Publish
What it is about?
Dremel is a columnar execution engine developed by Google for interactive analysis of large-scale datasets. It is mainly used within Google. Google later launched BigQuery as the public implementation of it - as a service for people to utilize the power of Dremel. BigQuery is a fully-managed and cloud-based interactive query service for massive datasets. This paper compares BigQuery to technologies like MapReduce, Hadoop and Data Warehouse solutions.
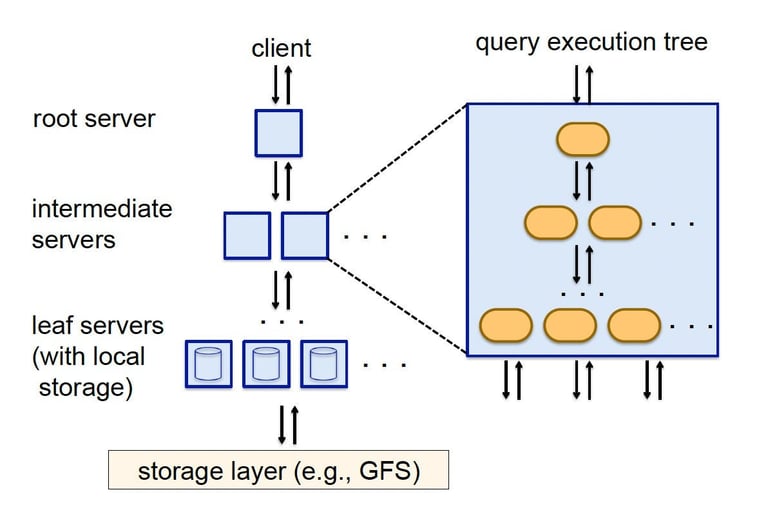
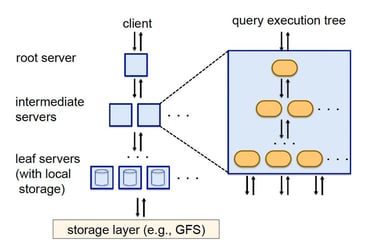
Basic Understandings
Dremel
Can scan billions of rows in seconds without an index
Cloud powered, massively parallel query service and can run parallel on thousands of servers
Can execute complex regular expression text matching on a huge file (30TB) in seconds - highly scalable.
Has a high compression ratio due to columnar storage; can easily aggregate results across thousands of machines using tree like architecture
MapReduce
The mapper extracts text and reducer aggregates the count of each word.
Adv: cost-effective highly scalable parallel data processor as it reduces the need for large distributed computing resources.
Applications: log analysis, recommendation engines, unstructured data processing, data mining, text mining
Limitation: Takes a long time to execute- so it is unsuited for ad-hoc analysis and trial and error methods - this is where Dremel shines as it can process big data easily.
BigQuery - Public version of Dremel
Google created BigQuery as a service to third-party developers via REST API, CLI, Web UI and other integrations with Google Cloud Storage.
Data Warehouse solutions
ROLAP: an RDB that requires indices to run OLAP queries
MOLAP: builds data cubes and data marts (requires lot of time) based on predefined dimensions.
Full-scan: without indexing, can perform speedy full table scan; suitable for ad hoc queries and trial/error analysis
Related Work
Dremel is similar to MapReduce as both tries to address fault tolerance, flexible data model, and in situ data processing. The columnar representation comes from the works published by Abadi and team. Data model and query language is from the studies of nested relations. It mentions other parallel data processing frameworks like Pig, Scope, and DryadLINQ,
Conclusion
BigQuery effectively query data of 35B rows without indexing - saving cost and time. Google launched BigQuery to allow people to utilize the power of Dremel, enabling enterprises and developers for processing Big Data. BigQuery is especially very helpful with ad-hoc OLAP/BI queries that require fast results. BigQuery has an extremely high full-scan query performance and cost effectiveness compared to other mechanisms.
Our Projects
Explore our diverse range of innovative projects.


Project A
Innovative solution for modern challenges.






Project B
Creative approach to community development.